Basic Concepts
Pipeline Design
Pyper follows the functional paradigm, which by design maximizes the modularity and composability of data flows. This pattern takes effect in the usage API on two levels:
- Python functions are the building blocks used to create
Pipelineobjects Pipelineobjects can themselves be thought of as functions
For example, to create a simple pipeline, we can wrap a function in the task class:
from pyper import task
def len_strings(x: str, y: str) -> int:
return len(x) + len(y)
pipeline = task(len_strings)
This defines pipeline as a pipeline consisting of a single task. It takes the parameters (x: str, y: str) and generates int outputs from an output queue:
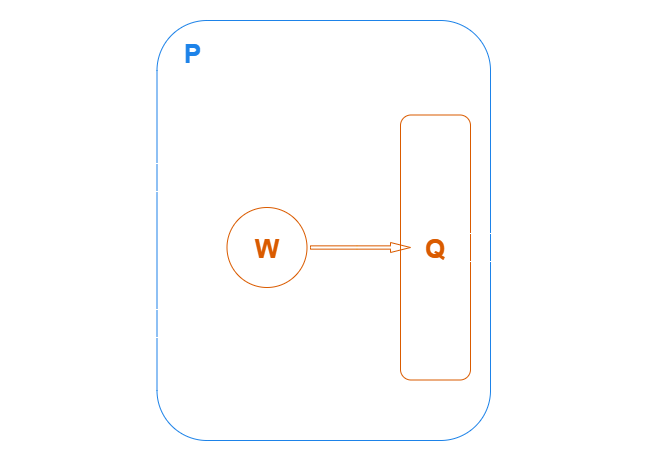
Key Concepts
- A Pipeline is a representation of data-flow (Pyper API)
- A task represents a single functional operation within a pipeline (user defined)
- Under the hood, tasks pass data along via workers and queues (Pyper internal)
Pipelines are composable components; to create a pipeline which runs multiple tasks, we can ‘pipe’ pipelines together using the | operator:
import time
from pyper import task
def len_strings(x: str, y: str) -> int:
return len(x) + len(y)
def sleep(data: int) -> int:
time.sleep(data)
return data
def calculate(data: int) -> bool:
time.sleep(data)
return data % 2 == 0
pipeline = (
task(len_strings)
| task(sleep, workers=3)
| task(calculate, workers=2)
)
This defines pipeline as a series of tasks, taking the parameters (x: str, y: str) and generating bool outputs:
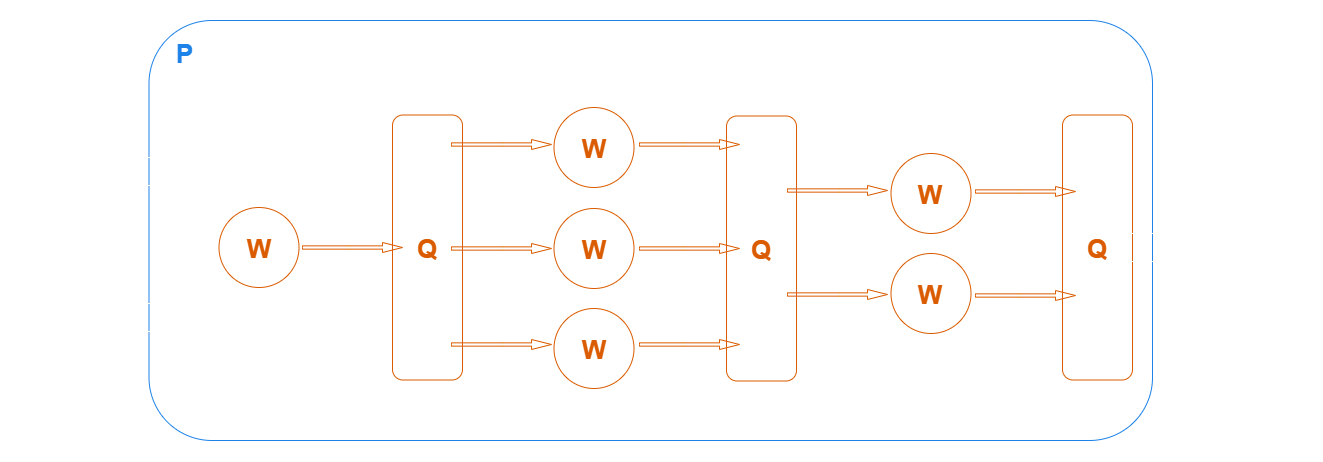
We can think of this pipeline as one function.
The internal behaviour handles, intuitively, taking the outputs of each task and passing them as inputs to the next, where tasks communicate with each other via queue-based data structures. Running a task with multiple workers is the key mechanism underpinning how concurrency and parallelism are achieved.
Next Steps
In the next few sections, we’ll go over some more details on pipeline usage. Skip ahead to see: