Composing Pipelines
Piping and the | Operator
The | operator (inspired by UNIX syntax) is used to pipe one pipeline into another. This is syntactic sugar for the Pipeline.pipe method.
from pyper import task, Pipeline
p1 = task(lambda x: x + 1)
p2 = task(lambda x: 2 * x)
p3 = task(lambda x: x - 1)
new_pipeline = p1 | p2 | p3
assert isinstance(new_pipeline, Pipeline)
# OR
new_pipeline = p1.pipe(p2).pipe(p3)
assert isinstance(new_pipeline, Pipeline)
This represents defining a new function that:
- takes the inputs of the first task
- takes the outputs of each task and passes them as the inputs of the next task
- finally, generates each output from the last task
if __name__ == "__main__":
for output in new_pipeline(4):
print(output)
#> 9
Consumer Functions and the > Operator
It is often useful to define resuable functions that process the results of a pipeline, which we’ll call a ‘consumer’. For example:
import json
from typing import Dict, Iterable
from pyper import task
def step1(limit: int):
for i in range(limit):
yield {"data": i}
def step2(data: Dict):
return data | {"hello": "world"}
class JsonFileWriter:
def __init__(self, filepath):
self.filepath = filepath
def __call__(self, data: Iterable[Dict]):
data_list = list(data)
with open(self.filepath, 'w', encoding='utf-8') as f:
json.dump(data_list, f, indent=4)
if __name__ == "__main__":
pipeline = task(step1, branch=True) | task(step2) # The pipeline
writer = JsonFileWriter("data.json") # A consumer
writer(pipeline(limit=10)) # Run
The > operator (again inspired by UNIX syntax) is used to pipe a Pipeline into a consumer function (any callable that takes an Iterable of inputs) returning simply a function that handles the ‘run’ operation. This is syntactic sugar for the Pipeline.consume method.
if __name__ == "__main__":
run = (
task(step1, branch=True)
| task(step2)
> JsonFileWriter("data.json")
)
run(limit=10)
# OR
run = (
task(step1, branch=True).pipe(
task(step2)).consume(
JsonFileWriter("data.json"))
)
run(limit=10)
Pyper comes with fantastic intellisense support which understands these operators and preserves parameter/return type hints from user-defined functions
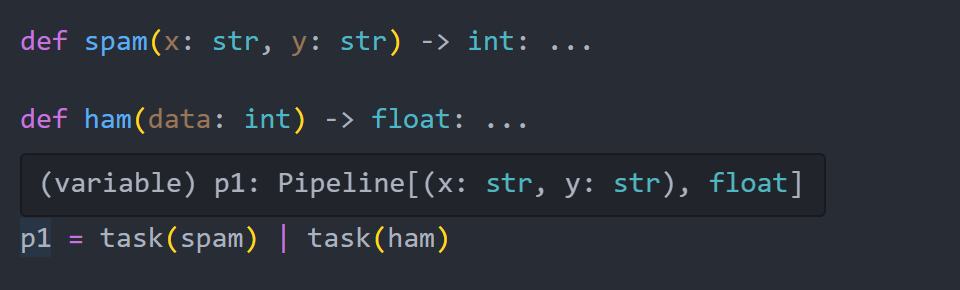
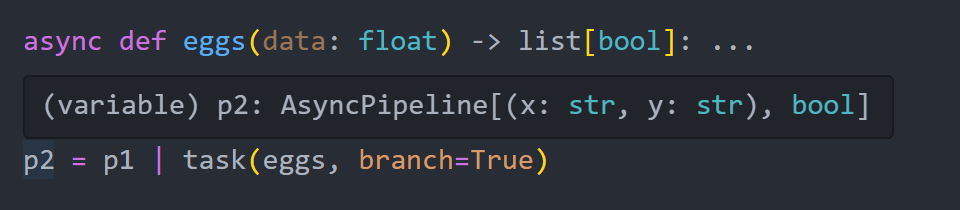
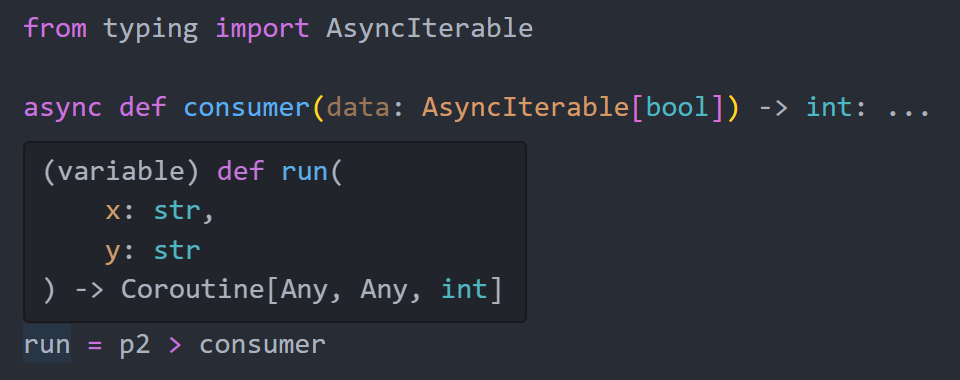
Nested Pipelines
Just like functions, we can also call pipelines from other pipelines, which facilitates defining data flows of arbitrary complexity.
For example, let’s say we have a theoretical pipeline which takes (source: str) as input, downloads some files from a source, and generates str outputs representing filepaths.
download_files_from_source = (
task(list_files, branch=True) # Return a list of file info
| task(download_file, workers=20) # Return a filepath
| task(decrypt_file, workers=5, multiprocess=True) # Return a filepath
)
This is a function which generates multiple outputs per source. But we may wish to process batches of filepaths downstream, after waiting for a single source to finish downloading. This means a piping approach, where we pass each individual filepath along to subsequent tasks, won’t work.
Instead, we can define download_files_from_source as a task within an outer pipeline, which is as simple as wrapping it in task like we would with any other function.
download_and_merge_files = (
task(get_sources, branch=True) # Return a list of sources
| task(download_files_from_source) # Return a batch of filepaths (as a generator)
| task(sync_files, workers=5) # Do something with each batch
)
download_files_from_sourcetakes a source as input, and returns a generator of filepaths (note that we are not settingbranch=True; a batch of filepaths is being passed along per source)sync_filestakes each batch of filepaths as input, and works on them concurrently
Asynchronous Code
Recall that an AsyncPipeline is created from an asynchronous function:
from pyper import task, AsyncPipeline
async def func():
return 1
assert isinstance(task(func), AsyncPipeline)
When piping pipelines together, the following rule applies:
Pipeline+Pipeline=PipelinePipeline+AsyncPipeline=AsyncPipelineAsyncPipeline+Pipeline=AsyncPipelineAsyncPipeline+AsyncPipeline=AsyncPipeline
In other words:
A pipeline that contains at least one asynchronous task becomes asynchronous
This reflects a (sometimes awkward) trait of Python, which is that async and await syntax bleeds everywhere – as soon as one function is defined asynchronously, you often find that many other parts program need to become asynchronous. Hence, the sync vs async decision is usually one made at the start of designing an application.
The Pyper framework slightly assuages the developer experience by unifying synchronous and asynchronous execution under the hood. This allows the user to define functions in the way that makes the most sense, relying on Pyper to understand both synchronous and asynchronous tasks within an AsyncPipeline.
Consumer functions will however need to adapt to asynchronous output. For example:
import asyncio
import json
from typing import AsyncIterable, Dict
from pyper import task
async def step1(limit: int):
for i in range(limit):
yield {"data": i}
def step2(data: Dict):
return data | {"hello": "world"}
class AsyncJsonFileWriter:
def __init__(self, filepath):
self.filepath = filepath
async def __call__(self, data: AsyncIterable[Dict]):
data_list = [row async for row in data]
with open(self.filepath, 'w', encoding='utf-8') as f:
json.dump(data_list, f, indent=4)
async def main():
run = (
task(step1, branch=True)
| task(step2)
> AsyncJsonFileWriter("data.json")
)
await run(limit=10)
if __name__ == "__main__":
asyncio.run(main())